Introduction
I competed in my first Kaggle contest and I learned a lot. My github repo was such a disorganized mess that I sometimes doubted I could even recreate these models. So I did the programmer thing:

I felt that most of my time was spent recording results, saving models, and trying to organize folders in a structured way. Halfway through I realize this could be automated, so I created the R package leadr.
Within an R project, leadr maintains a personal leaderboard for every model built. The package also handles model saving and organization. By the time I unit tested, documented, and built a pkgdown website leadr cost me days in the competition and my score no doubt suffered. Totally worth it.
What I learned about R Packages
I used many resoruces to get started on my package. Hadley’s R Packages, Parker’s R package blog post, and Broman’s package primer.
I also recommend you look at usethis. This package automates many of the various small tasks you need to do while building a package.
S3, Tibble, and Pillar
When recent versions of tibble supported colored output to consoles, I became really intrigued at the idea of programmatically coloring outputs to highlight important data at the console.
There is an excellent tibble vignette on using the pillar package to customize tibble printing. This, along with a custom S3 object, allowed me to customize certain column printing. Unfortunately, I realized there is no way to pass arguments to the pillar formatting tool, so I had to resort to a global variable hack. I am still pleased at the results.
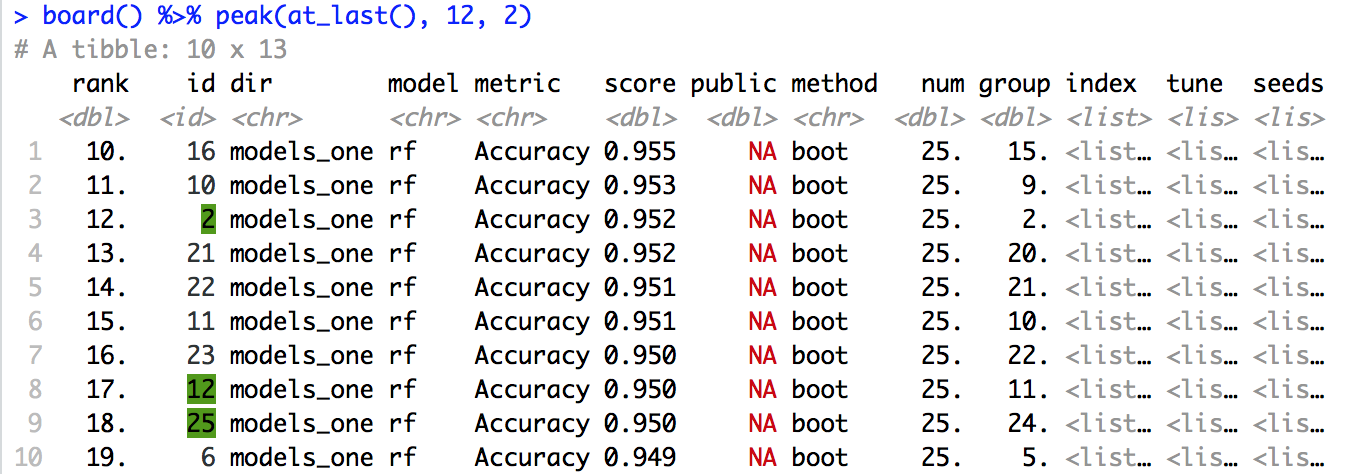
I’d love to be able to highlight an entire row, but that seems out of reach since each column has it’s own unique pillar formatting.
Non-Standard Evaluation
Hadley has been talking a lot recently about NSE, and there is a good tutorial on the dplyr website.
I ended up using dynamic NSE in a few different places. In the latter instance,
filtered <- model$pred %>%
dplyr::filter_(paste(column_names, "==", shQuote(column_values), collapse = "&"))I needed to use the deprecated underscored version that operates on strings, because I was filtering on an unknown number of columns (the column_names varies on the model). Therefore, I needed to use paste’s collapse functionality to programmatically concatenate as necessary. I wasn’t able to find any SO references to similiar situations, and haven’t come up with a NSE alternative.
What I learned about Machine Learning
I spent most of my time learning new tools instead of trying to optimize my accuracy. Even though this set me behind, I think this was a wise investment for future competitions.
Ensembles
One of my most enjoyable discoveries was stacked and blended ensembles. I wrote a brief tutorial as a leadr vignette that I recommend you check out. The basic idea can be summed up in this picture

taken from the article How to Rank 10% in Your First Kaggle Competition. As a model is trained on a 5-fold cross-validation set, the predictions on each out-of-fold section become features for a new ensemble model.
Keras
I know Keras has a great new interface to R, but I decided to use the Python version. Not only did I want to become more familiar with the Python side of data science, but I also wanted to take advantage of my Nvidia 970 on my PC while I built caret models on my laptop.
While I did implement a Convolution Neural Network and a Resnet, they did not perform as well as most other models. In my case, I think it was partly due to the fact that our training data set was small (178 observations) and that I don’t know how to effectively do regularization or dropout. Still a lot to learn for me here.
One Keras feature I found immediately useful was the ImageDataGenerator class. I was easily able to visualize various image transformations and print out images to explore the data.

Each row is the same three pictures: untransformed, centered, and scaled respectively.
Conclusions
I’m definitely aware of the limitations of complicated modeling:
The panelists value string handling, data munging, and adding/dividing but think that complicated modeling is given too much focus relative to how important it is in the real world. #rstudioconf pic.twitter.com/l3FdwnFKyZ
— Julia Silge (@juliasilge) February 4, 2018
But I still think a Kaggle contest is a great opporunity to get some hands-on experience with data and to find some motivation for R packages.